
备战前端面试—React篇
React 基础
React 概念
考点1:React 特性
说说对React的理解?有哪些特性?
React 是应用于构建 UI 的 JavaScript 库,只提供了 UI 层面的解决方案。
遵循组件设计模式、声明式编程范式、函数式编程。使用 VirtualDOM 代替真实 DOM 操作,遵循高阶组件到低阶组件的单向数据流传递。
由于各个组件都是函数,组件之间可自由组合、嵌套,实现了组件的复用和解耦。同时,在维护时也只需要关注于组件本身。
可以以
render()或return的方式输出 XML 格式的内容,即 JSX。总结,特性有:
组件设计模式
一切皆为组件,可组合,可重用,可维护。
声明式编程范式
<Map zoom={4} center={lat, lng}> <Marker position={lat, lng} title={'Hello Marker'}/> </Map>关注的是你要做什么,而不是如何做。做的部分交给 React 即可。
函数式编程
const Header = () => { return( <Jumbotron style={{backgroundColor:'orange'}}> <h1>TODO App</h1> </Jumbotron> ) }函数是一等公民,支持作为参数传递,可以从函数返回,也可以赋值给变量。
JSX 语法
return (<div>Hello{this.props.name}</div>);最终会被
babel编译为合法的JS语句调用。VDOM
本质上是以
JavaScript对象形式存在的对DOM的描述。虚拟DOM对象的节点与真实DOM的属性一一对应。单向数据流
单向响应的数据流会比双向绑定的更安全,速度更快(少一步操作)。
什么是 JSX?
实际上,JSX 仅仅只是
React.createElement(component, props, ...children)函数的语法糖(React 17 变更为调用新的入口函数jsx())。在使用过程中会被
babel进行编译转化成JS代码:const vDom = React.createElement( 'h1', { className: 'hClass', id: 'hId' }, 'hello world' )JSX就是为了简化直接调用React.createElement()方法:- 第一个参数是标签名,例如h1、span、table…
- 第二个参数是个对象,里面存着标签的一些属性,例如 id、class 等
- 第三个参数是节点中的文本
说说 Real DOM和 Virtual DOM 的区别?优缺点?
Real DOM,真实DOM,意思为文档对象模型,是一个结构化文本的抽象,在页面渲染出的每一个结点都是一个真实DOM结构。Virtual DOM,本质上是以JavaScript对象形式存在的对DOM的描述,创建虚拟DOM目的就是为了更好将虚拟的节点渲染到页面视图中。在
React中,JSX是其一大特性,可以让你在JS中通过使用XML的方式去直接声明界面的DOM结构。const vDom = <h1>Hello World</h1> // 创建h1标签 const root = document.getElementById('root') // 找到<div id="root"></div>节点 ReactDOM.render(vDom, root) // 把创建的h1标签渲染到root节点上ReactDOM.render()用于将创建好的虚拟DOM节点插入到某个真实节点上,并渲染到页面上。
区别:
- 修改虚拟
DOM不会造成重绘回流,而真实DOM会频繁重绘回流。
- 虚拟
DOM的总损耗是虚拟DOM增删改+真实DOM差异增删改+回流与重绘,真实DOM的总损耗是真实DOM完全增删改+回流与重绘。
举个例子来说,同样更新 10 个
DOM节点,虚拟DOM不会立即操作DOM,而是将这 10 次更新的diff内容保存到本地的一个js对象中,最终将这个js对象一次性attach到DOM树上,避免大量的无谓计算。
真实
DOM的优势:- 易用
缺点:
- 效率低,解析速度慢,内存占用量过高
- 性能差,频繁操作真实
DOM,易于导致重绘与回流
虚拟
DOM的优势:- 简单方便:如果使用手动操作真实
DOM来完成页面,繁琐又容易出错,在大规模应用下维护起来也很困难 - 性能方面:使用
Virtual DOM,能够有效避免真实DOM树频繁更新,减少多次重绘与回流,提高性能 - 跨平台:
React借助虚拟DOM, 带来了跨平台的能力,一套代码多端运行
缺点:
- 在一些性能要求极高的应用中虚拟
DOM无法进行针对性的极致优化 - 首次渲染大量
DOM时,由于多了一层虚拟DOM的计算,速度比正常稍慢
- 修改虚拟
key 有什么作用, 可以省略吗?
我们在编程时直接书写的
jsx代码,实际上是会被编译成ReactElement对象,所以key是ReactElement对象的一个属性。key属性的作用是用于判断元素是新创建的还是被移动的元素,从而减少不必要的元素渲染。所有
ReactElement对象都有key,key的默认值是null。由于
DOM节点的移动操作开销是比较昂贵的,没有key的情况下要比有key的性能更好。因此对于简单列表渲染而言,最好省略
key:// 1.加key <div key='1'>1</div> <div key='1'>1</div> <div key='2'>2</div> <div key='3'>3</div> <div key='3'>3</div> ========> <div key='2'>2</div> <div key='4'>4</div> <div key='5'>5</div> <div key='5'>5</div> <div key='4'>4</div> // 操作:节点2移动至下标为2的位置,节点4移动至下标为4的位置。 // 2.不加key <div>1</div> <div>1</div> <div>2</div> <div>3</div> <div>3</div> ========> <div>2</div> <div>4</div> <div>5</div> <div>5</div> <div>4</div> // 操作:修改第1个到第5个节点的innerText如果在列表的末尾插入新元素,是可以省略
key的。但如果插入头部或中间,从插入位置开始的元素都将受到影响。列表内元素为复杂组件时,最好加上key,此时移动的性能消耗要小于销毁重新创建。说说你对immutable的理解?如何应用在react项目中?
Immutable,不可改变的,在计算机中,即指一旦创建,就不能再被更改的数据。
对
Immutable对象的任何修改或添加删除操作都会返回一个新的Immutable对象。Immutable实现的原理是Persistent Data Structure(持久化数据结构):- 用一种数据结构来保存数据
- 当数据修改时,返回一个对象,这个对象会尽可能地利用之前的数据结构而不造成浪费。
也就是使用旧数据创建新数据时,要保证旧数据同时可用且不变,同时为了避免
deepCopy把所有节点都遍历一遍带来的性能损耗,Immutable使用了Structural Sharing(结构共享)。如果对象树中一个节点发生变化,只修改这个节点和受它影响的父节点,其它节点则进行共享。
应用:
使用
Immutable可以给React应用带来性能的优化,主要体现在减少渲染的次数。在做
react性能优化的时候,为了避免重复渲染,我们会在shouldComponentUpdate()中做对比,当返回true执行render方法(函数组件用React.memo,浅比较 state 和 props)。在使用
redux过程中也可以结合Immutable,不使用Immutable前修改一个数据需要做一个深拷贝import '_' from 'lodash'; const Component = React.createClass({ getInitialState() { return { data: { times: 0 } } }, handleAdd() { let data = _.cloneDeep(this.state.data); data.times = data.times + 1; this.setState({ data: data }); } }使用 Immutable 后:
getInitialState() { return { data: Map({ times: 0 }) } }, handleAdd() { this.setState({ data: this.state.data.update('times', v => v + 1) }); // 这时的 times 并不会改变 console.log(this.state.data.get('times')); }说说 React 的 diff 算法?
diff算法就是更高效地通过对比新旧Virtual DOM来找出真正的DOM变化之处。传统
diff算法通过循环递归对节点进行依次对比,效率低下,算法复杂度达到O(n^3),react将算法进行一个优化,复杂度降到了O(n)。react中diff算法主要遵循三个层级的策略:tree 层级
DOM节点跨层级的操作不做优化,只会对相同层级的节点进行比较。只有删除、创建操作,没有移动操作。component 层级
如果是同一个类的组件,则会继续往下
diff运算,如果不是一个类的组件,那么直接删除这个组件下的所有子节点,创建新的。element 层级
对于比较同一层级的节点,每个节点在对应的层级用唯一的
key作为标识。通过key可以准确地发现新旧集合中的节点都是相同的节点,因此无需进行节点删除和创建,只需要将旧集合中节点的位置进行移动,更新为新集合中节点的位置。
说说 React 的 patch 算法?
React构建虚拟标签,执行组件的生命周期,更新state,计算diff等,这一系列的操作都是在virtualDOM中执行的,此时浏览器并未显示出更新的数据。React Patch实现了最后这关键的一步,将tree diff算法计算出来的差异队列更新到真实的DOM节点上,最终让浏览器能够渲染出更新的数据。
Patch主要是通过遍历差异队列实现的,遍历差异队列时,通过更新类型进行相应的插入、移动和移除等操作。
React并不是计算出一个差异就执行一次patch,而是计算出全部的差异并放入差异队列后,再一次性的去执行Patch方法完成真实的DOM更新。
React 的 patch 发生在 commit 阶段之前。React找到差异后并不及时立刻更新。而是对该 Fiber 节点打上一个
tag(Update, Placement, Delete)。进入commit 阶段,将调用 react-dom 遍历存在 tag 的 Fiber ,根据 tag 的类型执行对应的 DOM 更新。说说React render方法的原理?在什么时候会被触发?
首先,
render函数在react中有两种形式:在类组件中,指的是
render方法:class Foo extends React.Component { render() { return <h1> Foo </h1>; } }在函数组件中,指的是函数组件本身:
function Foo() { return <h1> Foo </h1>; }在
render函数中,我们会编写jsx,其中的每个节点最终转化为ReactElement对象。
React15 VDOM架构:render过程中,React 会将新的render函数构造的VDOM与旧的比较(diff 算法)。然后调用渲染器,真实 DOM 变更,线程交给浏览器渲染,界面得到更新。
Fiber架构:为了解决
diff流程不可中断的问题,Fiber架构中将整个更新流程分为了两个阶段。Render阶段:异步可中断地
diff新旧Fiber树,找到差异后并不及时立刻更新。而是对该Fiber节点打上一个tag(Update, Placement, Delete)。Commit阶段:遍历存在
tag的FiberNode,根据tag的类型执行对应的DOM更新。新架构的优势在于将 diff 和渲染的流程分开。并基于 Schedule 实现异步可中断,解决了复杂运算大量占用 JS线程的问题。
render的执行时机主要分成两种:应用初次加载。
存在组件 state、props 更新。
生命周期
考点1:生命周期阶段
说说 React 生命周期有哪些不同阶段?
整个组件的生命周期包括创建、初始化数据、编译模板、挂载 DOM -> 渲染、更新 -> 渲染、卸载。
从
react16.4后主要分三个阶段:- 创建
- 更新
- 卸载

考点2:生命周期方法
能详细介绍生命周期每个阶段对应的方法吗?
生命周期方法多用于类组件。在处理函数式组件时,可以使用
useEffect钩子来复制生命周期行为。
创建阶段:
constructor
实例过程自动调用,通过
super关键字获取来自父组件的props,在该方法中通常操作为初始化 state 或在 this 上挂载方法。getDerivedStateFromProps
新增的静态方法,不能访问组件实例。在组件创建和更新阶段,
props和state变化时,在render之前被调用。第一个参数为即将更新的props,第二个参数为上一个状态的state。可以比较props和state来加一些限制条件,防止无用的state更新。该方法需要返回一个新的对象作为新的state或者返回null表示state状态不需要更新。render
类组件必须实现的方法,渲染 DOM 结构,可以访问组件的
props和state。componentDidMount
在
render之后被调用。组件挂载到真实节点后执行。多用于执行数据获取、事件监听操作。
更新阶段:
getDrivedStateFromProps
同上
shouldComponentUpdate
用于告知组件基于当前的
prop和state,需不需要重新渲染组件,默认情况返回true。在更新阶段,
props和state变化时,在render之前被调用。通过返回true或者false告知组件更新与否。一般情况,不建议在该周期方法中进行深层比较,会影响效率。render
同上
getSnapshotBeforeUpdate
在 render 之后调用,在 RealDOM 更新之前执行。返回一个
Snapshot,记录组件在更新之前的信息,作为第三个参数传递给 componentDidUpdate。componentDidUpdate
组件在 RealDOM 中更新结束后触发。可以根据前后的
props和state的变化做相应的操作,如获取数据,修改DOM样式等。
卸载阶段:
componentWillUnmount
此方法用于组件卸载前,清理一些注册监听事件,或者取消订阅的网络请求等。一旦一个组件实例被卸载,其不会被再次挂载,而只可能是被重新创建。
state 与 prop
考点1:概念
状态(state)和属性(props)有何不同?
一个组件的显示形式可以由其数据状态和外部参数决定。数据状态就是 state,而外部参数就是 props。
修改组件状态,一般是通过 setState。
setState()将对组件 state 的更改排入队列,并通知 React 需要使用更新后的 state 重新渲染此组件及其子组件。这是用于更新用户界面以响应事件处理器和处理服务器数据的主要方式。将setState()视为请求而不是立即更新组件的命令。为了更好的感知性能,React 会延迟调用它,然后通过一次传递更新多个组件。React 并不会保证 state 的变更会立即生效。组件从概念上看就是一个函数,可以接受一个参数作为输入值,这个参数就是
props,所以可以把props理解为从外部传入组件内部的数据。react具有单向数据流的特性,所以他的主要作用是从父组件向子组件中传递数据。在子组件中,
props在内部是不可变的,如果想要改变它,只能通过外部组件传入新的props来重新渲染子组件,否则子组件的props和展示形式不会改变。
相同点:
- 两者都是 JavaScript 对象
- 两者都是用于保存信息
- props 和 state 都能触发渲染更新
区别:
- props 是外部传递给组件的,而 state 是在组件内被组件自己管理的,一般在 constructor 和钩子中初始化
- props 在组件内部是不可修改的,但 state 在组件内部可以进行修改
- state 是多变的、可以修改
考点2:setState
为什么调用 setState 而不是直接改变 state?
直接修改 state 的值,并不会让组件重新渲染。 React 的核心思想是不可变数据结构(Immutable)。
实际上 setState 是一种任务驱动式的更新。任务的出现会触发更新调度。
另外,setState 创建更新时要从 scheduler 中拿到触发本次更新的优先级,将优先级加入到任务中。
setState 一定是异步?
采用 fiber 架构以后,移除了
isBatchingUpdate这个标识。这之后 react 的执行其实分成两种情况:同步:
首先在
legacy模式下。ReactDOM.render( <App />, document.getElementById('root'), );在执行上下文为
NoContext的时候去调用setState。- 可以使用异步调用如
setTimeout,Promise,MessageChannel等。 - 可以监听原生事件,注意不是合成事件,在原生事件的回调函数中执行 setState 就是同步的。
- 可以使用异步调用如
异步:
如果是合成事件中的回调,
executionContext |= DiscreteEventContext,所以不会进入flushSyncCallbackQueue()分支,最终表现出异步。concurrent 模式下都为异步。
ReactDOM.createRoot(rootElement).render(<App />);
回归源码(fiber架构),看看 reconciler 是如何决定是否同步渲染调度的:
export function scheduleUpdateOnFiber( fiber: Fiber, expirationTime: ExpirationTime ) { const priorityLevel = getCurrentPriorityLevel(); if (expirationTime === Sync) { if ( // Check if we're inside unbatchedUpdates (executionContext & LegacyUnbatchedContext) !== NoContext && // Check if we're not already rendering (executionContext & (RenderContext | CommitContext)) === NoContext ) { performSyncWorkOnRoot(root); } else { ensureRootIsScheduled(root); schedulePendingInteractions(root, expirationTime); if (executionContext === NoContext) { // Flush the synchronous work now, unless we're already working or inside // a batch. This is intentionally inside scheduleUpdateOnFiber instead of // scheduleCallbackForFiber to preserve the ability to schedule a callback // without immediately flushing it. We only do this for user-initiated // updates, to preserve historical behavior of legacy mode. flushSyncCallbackQueue(); } } } else { // Schedule a discrete update but only if it's not Sync. if ( (executionContext & DiscreteEventContext) !== NoContext && // Only updates at user-blocking priority or greater are considered // discrete, even inside a discrete event. (priorityLevel === UserBlockingPriority || priorityLevel === ImmediatePriority) ) { // This is the result of a discrete event. Track the lowest priority // discrete update per root so we can flush them early, if needed. if (rootsWithPendingDiscreteUpdates === null) { rootsWithPendingDiscreteUpdates = new Map([[root, expirationTime]]); } else { const lastDiscreteTime = rootsWithPendingDiscreteUpdates.get(root); if ( lastDiscreteTime === undefined || lastDiscreteTime > expirationTime ) { rootsWithPendingDiscreteUpdates.set(root, expirationTime); } } } // Schedule other updates after in case the callback is sync. ensureRootIsScheduled(root); schedulePendingInteractions(root, expirationTime); } }可以看到,是否同步渲染调度决定代码是
flushSyncCallbackQueue(),它会取消schedule 调度并刷新同步回调队列,立即进入fiber树构造过程。当执行setState下一行代码时,fiber树已经重新渲染了,故setState体现为同步。正常情况下,不会取消
schedule 调度。由于schedule 调度是通过MessageChannel触发(宏任务),故体现为异步。进入该分支的条件:
- 必须是
legacy模式,concurrent模式下expirationTime不会为Sync executionContext === NoContext,ReactFiberWorkLoop的执行上下文必须要为NoContext。
两个条件缺一不可。
在 react 最新版本中不仅仅是
setState了, 在对 function 类型组件中的 hook 进行操作时也是一样, 最终决定setState是同步渲染还是异步渲染的关键因素是ReactFiberWorkLoop工作空间的执行上下文。说说 React 中的 setState 执行机制
当需要修改组件的状态时,
React推荐我们使用setState的方式而不是直接赋值。如果直接修改组件内
state的值,组件并不会重新渲染,但是state的值其实已经改变了,绕过React来修改state,可能会产生麻烦。这是因为
React并不像vue2中调用Object.defineProperty实现数据响应式或者Vue3调用Proxy监听数据对象的变化。必须通过setState方法来告知React组件state已经发生了改变。这其实与
setState的执行机制有关。源码比较复杂,故简述。
setState入口:Component.prototype.setState = function (partialState, callback) { invariant( typeof partialState === "object" || typeof partialState === "function" || partialState == null, "setState(...): takes an object of state variables to update or a " + "function which returns an object of state variables." ); this.updater.enqueueSetState(this, partialState, callback, "setState"); };首先,
setState传入了两个参数:partialState,通过invariant函数验证我们知道需要为对象、函数、nullcallback回调函数
partialState这个参数传入的是state,也许是整个state,也许是部分,但是最后都会被执行浅合并(代码略)。接下来调用了
this.updater:this.updater.enqueueSetState(this, partialState, callback, "setState");
updater:
定义在
react\packages\react-reconciler\src\ReactFiberClassComponentconst classComponentUpdater = { isMounted, enqueueSetState(inst, payload, callback) { // 1. 获取class实例对应的fiber节点 const fiber = getInstance(inst); // 2. 创建update对象 const eventTime = requestEventTime(); const lane = requestUpdateLane(fiber); // 确定当前update对象的优先级 const update = createUpdate(eventTime, lane); update.payload = payload; if (callback !== undefined && callback !== null) { update.callback = callback; } // 3. 将update对象添加到当前Fiber节点的updateQueue队列当中 enqueueUpdate(fiber, update); // 4. 进入reconcier运作流程中的`输入`环节 scheduleUpdateOnFiber(fiber, lane, eventTime); // 传入的lane是update优先级 }, };此时
setState将更新需求发给react-reconciler(调和器),让其把更新需求转换成一个update task,等待调度。之后
update task将推入updateQueue,调度器scheduler通过任务调度循环来依次执行更新队列的task,直到队列清空。一句话总结:
setState 调用 reconciler 注册 update task,并推入 updateQueue,最后送入 scheduler 批处理 updateQueue 中的 task,返回 reconciler 构造新 fiber 树。
考点3:prop
什么是 prop drilling,如何避免它?
Prop drilling即 prop 钻探,通常是指数据从父组件向下传递到层级较低的子组件的过程,通过了一些除了传递以外不需要 props 本身的组件。可以通过重构组件,避免过早将组件分为更小的组件,并将公用状态保存在最接近的父级中。如果需要将数据传递到深层次的组件中,则需要借助一些状态管理工具:React 的 Context API 或专用的状态管理库(例如 Redux)。
React中组件之间如何通信?
组件传递的方式有很多种,根据传送者和接收者可以分为如下:
父组件向子组件传递
比较简单,只需要在子组件标签内传递参数,子组件以 props 接收。
子组件向父组件传递
父组件向子组件传递函数,子组件调用函数,将参数传给父组件。
兄弟组件之间的通信
如果是兄弟组件之间的传递,则父组件作为中间层来实现数据的互通,通过使用父组件传递。
父组件向后代组件传递
可以 props 传递,更推荐使用
context,可以共享数据,其他后代组件都能读取对应的数据。非关系组件传递
使用全局状态管理库,如
redux。
Hook
考点1:概念
Hook 是什么? 什么时候会用 Hook?
在组件之间复用状态逻辑很难,复杂 class 组件状态将难以理解,为了解决这些痛点,引入了 Hook。
Hook 是一个特殊的函数,它允许你在函数组件中也可以拥有一些类组件的特性,比如
useState是允许你在React函数组件中添加state的Hook。Hook 避免了类组件需要的额外开支,比如创建类实例和在构造函数中绑定事件的成本。符合语言习惯的代码在使用 Hook 之后不需要很深的组件树嵌套,减少了 React 的工作量。
所以,使用 Hook能更优雅地代替 class,且性能更高,从开发者的角度来讲,我们应该拥抱 Hook 带来的便利。
考点2:常用 Hook
你平时常用的 hook 有哪些?在使用 hook 中遇到过什么问题?
hook 可分为两种类别:
状态 hook:
useState/useReducer:可以在函数内部添加状态,useState其实是useReducer的简易封装。useCallback/useMemo:用来保存函数、计算值,只有在依赖项改变时(浅比较,值相同认为不变)才重新计算。useRef:返回一个 ref 对象,在其 current 属性上保存传入的参数。useContext:接收一个 context 对象,并返回当前的 value 值。副作用 hook:
useEffect:最标准的副作用 hook。接收一个回调函数,作为在界面渲染完后执行的副作用。useLayoutEffect:执行于界面渲染之前,在 DOM 变更时触发的副作用。自定义 hook:如果要实现
副作用,必须直接或间接的调用useEffect。
常见的问题:
使用
useEffect时如果依赖项中存在对象类型要小心,最好使用useCallback/useMemo来处理该依赖,因为每次重新渲染都会生成新对象,浅层比较结果总为 false。小心闭包陷阱,
useEffect回调函数中可能拿到的是闭包中的值。可以将其添加到依赖,每次变化时都能拿到最新的值。也可使用useRef来记忆这个 state 对象,通过引用访问就能拿到最新的值。
useRef 保证的是每次重渲染创建的 ref 对象的引用不变。使用 useRef 对值进行包装,其实就是将其作为自己的 current 属性,因此每次更新都是在修改同一个引用。
useEffect 和 useLayoutEffect 的区别?
useEffect 在渲染时是异步执行,并且要等到浏览器将所有变化渲染到屏幕后才会被执行。
useLayoutEffect 在渲染时是同步执行,其执行时机与 componentDidMount,componentDidUpdate 一致。
useLayoutEffect 会阻塞浏览器渲染(JS 主线程和浏览器渲染线程互斥),此时真实 DOM 已经发生改变,而浏览器渲染还未进行,所以表现为在DOM 变化后,渲染之前执行。
因此,建议将修改 DOM 的操作放到 useLayoutEffect 中,通过这种方式只需要一次回流重绘,就可以完成界面更新。
说说对React refs 的理解?应用场景?
React中的Refs提供了一种方式,允许我们访问DOM节点或在render方法中创建的React元素本质为
ReactDOM.render()返回的组件实例,如果是渲染组件则返回的是组件实例,如果渲染dom则返回的是具体的dom节点。创建
ref的形式有三种:传入字符串,使用时通过 this.refs 传入的字符串的格式获取对应的元素。
class MyComponent extends React.Component { constructor(props) { super(props); this.myRef = React.createRef(); } render() { return <div ref="myref" />; } } this.refs.myref.innerHTML = "hello";传入对象,对象是通过 React.createRef() 方式创建出来,使用时获取到创建的对象中存在 current 属性就是对应的元素。
class MyComponent extends React.Component { constructor(props) { super(props); this.myRef = React.createRef(); } render() { return <div ref={this.myRef} />; } } const node = this.myRef.current;传入函数,该函数会在 DOM 被挂载时进行回调,这个函数会传入一个 元素对象,可以自己保存,使用时,直接拿到之前保存的元素对象即可。
class MyComponent extends React.Component { constructor(props) { super(props); this.myRef = React.createRef(); } render() { return <div ref={element => this.myref = element} />; } } const node = this.myref传入hook,hook是通过 useRef() 方式创建,使用时通过生成 hook 对象的 current 属性就是对应的元素。
function App(props) { const myref = useRef() return ( <> <div ref={myref}></div> </> ) } const node = myref.current;
下面的场景使用
refs非常有用:- 对Dom元素的焦点控制、内容选择、控制
- 对Dom元素的内容设置及媒体播放
- 对Dom元素的操作和对组件实例的操作
- 集成第三方 DOM 库
React 原理
宏观架构
考点1:React 核心包
React 核心包有哪些?
从宏观结构上看,有以下核心包:
react
react 基础包, 只提供定义 react 组件(
ReactElement)的必要函数,一般来说需要和渲染器(react-dom,react-native)一同使用。在编写react应用的代码时,大部分都是调用此包的 api。react-dom
react 渲染器之一,是连接 react 与 web 的桥梁。将 react-reconciler 的运行结果输出到 web 界面上,大多数情况下能使用到此包的只有一个入口函数
ReactDOM.render(<App/>, document.getElementByID('root')),其余使用的 api,基本是react包提供的。react-reconciler
react 运行的核心包,综合协调 react、react-dom、react-scheduler 各包之间的调用与配合。管理 react 应用状态的输入和结果的输出,将输入信号最终转化为输出信号传递给渲染器。
暴露
api函数(如:scheduleUpdateOnFiber),供给其他包(如react包)调用。接收输入(
schedulerUpdateOnFiber),将 fiber 树生成逻辑封装到回调函数中(涉及 fiber 树结构,调和算法、updateQueue等)。把此回调函数(
performSyncWorkOnRoot或performConcurrentWorkOnRoot)送入 scheduler 进行调度。由 react-scheduler 控制回调执行的时机,在内存中创建出与
fiber对应的DOM节点,构造新的fiber树。再调用渲染器(如
react-dom,react-native等)将最后的 fiber 树结构反映到页面上react-scheduler
调度机制的核心实现。控制由 react-reconciler 送入的回调函数的执行时机。在 concurrent 模式下可实现任务分片,实现可中断渲染。
其核心任务是执行回调。
react 内核 3 个包的主要职责和调用关系?
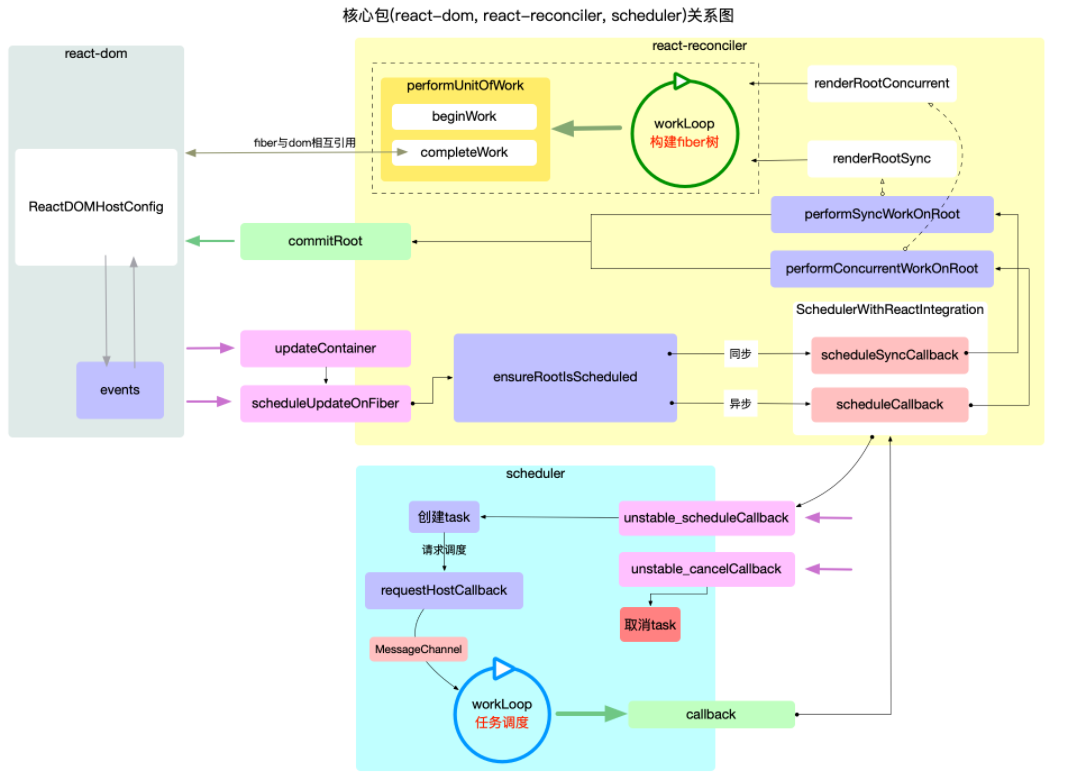
考点2:工作循环
有没有了解过 React 工作循环 (workLoop)?
React 的工作循环可分为两种:
任务调度循环:Scheduler.js 的调度循环,确保控制所有任务(
task)的调度。fiber 构造循环:源码位于ReactFiberWorkLoop.js,控制 fiber 树的构造,整个过程是一个深度优先遍历。
区别与联系:
任务调度循环是以二叉堆为数据结构,循环执行堆的顶点,直到堆被清空。fiber构造循环是以树为数据结构, 从上至下执行深度优先遍历。任务调度循环的逻辑偏向宏观,它调度的是每一个任务(task),而不关心这个任务具体是干什么的(甚至可以将Scheduler包脱离react使用),具体任务其实就是执行回调函数performSyncWorkOnRoot或performConcurrentWorkOnRoot。fiber构造循环的逻辑偏向具体实现,它只是任务(task)的一部分(如performSyncWorkOnRoot包括fiber树的构造,DOM渲染,调度检测),只负责fiber树的构造。fiber构造循环是任务调度循环中的任务(task)的一部分。它们是从属关系,每个任务都会重新构造一个fiber树。
Fiber 模型
考点1:Fiber 树构造
什么是 fiber 树?
fiber 树是通过 ReactElement 树生成的。JSX 将被转换成 ReactElement,互相之间形成联系组成一颗 ReactElement 树,用来驱动 fiber 树。所以 fiber 树的构造,其实就是 ReactElement 对象到 fiber 对象的转化过程。
fiber 树是 DOM 树的数据模型,是为每一个 DOM 节点附加的任务机制对象,fiber 树驱动 DOM 树,最终由 render 在 diff 计算后渲染到页面上。
fiber 树是一个单链表树结构,并且采用**双缓冲技术(double buffering)**:
在更新时内存里会同时存在 2 棵
fiber树,代表当前界面的fiber树currentFiber Tree,以及另一颗正在构造的fiber树WorkInProgress Tree,当构造完成之后,将其作为新的 fiber 树,并丢弃旧的 fiber 树。fiber 树造构建过程?
其实也分两种情况:
初次构造:
React 应用首次启动时,界面还没有渲染,此时不会进行 fiber 树对比,相当于直接创建一颗全新的树。
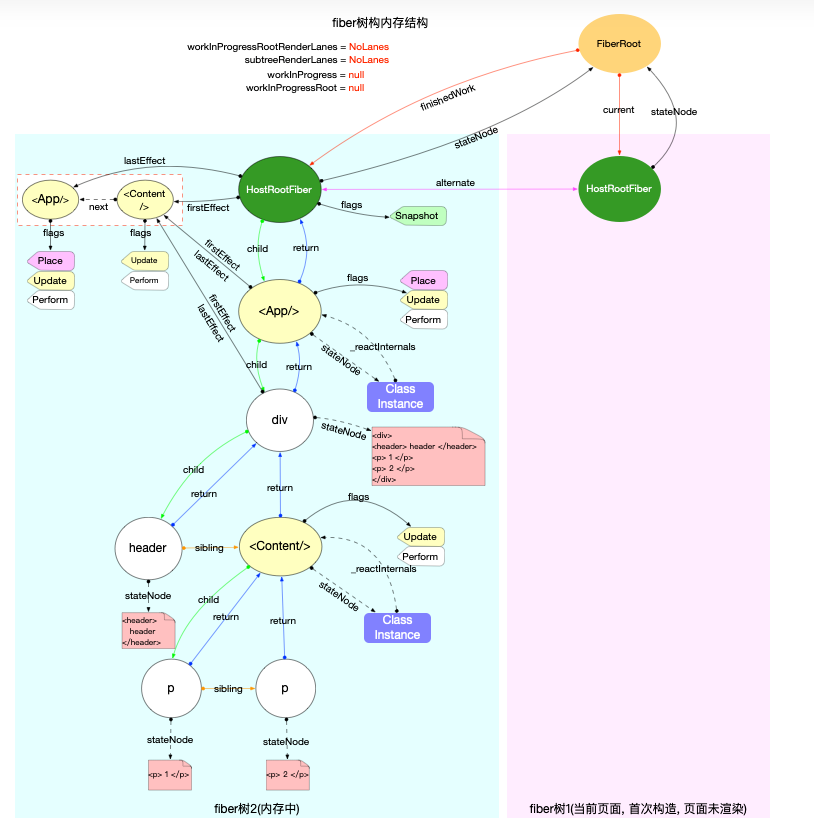
对比更新:
界面已渲染,如果发生更新,新的 fiber 树需要和旧 fiber 树对比,最后构造的 fiber 树可能是全新的,也可能是部分更新的。

考点2:Fiber 树渲染
fiber 树的渲染逻辑?
根据是否调用渲染分为三个阶段:
渲染前
为接下来的正式渲染做一些准备工作,包括设置全局状态(更新
fiberRoot上的属性),重置全局变量(workInProgressRoot,workInProgress等),再次更新副作用队列。渲染中
处理副作用队列,调用渲染器将最新的 DOM 节点(已经在内存中,只是还没渲染)渲染到界面上。
渲染后
在渲染完成后, 需要做一些重置和清理工作。
清除副作用队列:
- 由于副作用队列是一个链表,由于单个
fiber对象的引用关系,无法被gc回收. - 将链表全部拆开,当
fiber对象不再使用的时候,可以被gc回收
检测更新:
- 在整个渲染过程中,有可能产生新的
update(比如在componentDidMount函数中,再次调用setState())。 - 如果是常规(异步)任务,不用特殊处理,调用
ensureRootIsScheduled确保任务已经注册到调度中心即可。 - 如果是同步任务,则主动调用
flushSyncCallbackQueue(无需再次等待 scheduler 调度),再次进入 fiber 树构造循环。
- 由于副作用队列是一个链表,由于单个
优先级管理
考点1:优先级体系
React 是怎样进行优先级管理的?
在
React@17.0.2源码中, 一共有2套优先级体系和1套转换体系。React内部对于优先级的管理,贯穿运作流程的 4 个阶段(从输入到输出),根据其功能的不同,可以分为 3 种类型:fiber优先级(LanePriority): 位于react-reconciler包, 也就是Lane(车道模型)。export const SyncLanePriority: LanePriority = 15; export const SyncBatchedLanePriority: LanePriority = 14; const InputDiscreteHydrationLanePriority: LanePriority = 13; export const InputDiscreteLanePriority: LanePriority = 12; // ..... const OffscreenLanePriority: LanePriority = 1; export const NoLanePriority: LanePriority = 0;与
fiber构造过程相关的优先级(如fiber.updateQueue,fiber.lanes)都使用LanePriority。调度优先级(
SchedulerPriority): 位于scheduler包。export const NoPriority = 0; export const ImmediatePriority = 1; export const UserBlockingPriority = 2; export const NormalPriority = 3; export const LowPriority = 4; export const IdlePriority = 5;与
scheduler调度中心相关的优先级使用SchedulerPriority。优先级等级(
ReactPriorityLevel) : 位于react-reconciler包中的SchedulerWithReactIntegration.js,负责上述 2 套优先级体系的转换。export const ImmediatePriority: ReactPriorityLevel = 99; export const UserBlockingPriority: ReactPriorityLevel = 98; export const NormalPriority: ReactPriorityLevel = 97; export const LowPriority: ReactPriorityLevel = 96; export const IdlePriority: ReactPriorityLevel = 95; // NoPriority is the absence of priority. Also React-only. export const NoPriority: ReactPriorityLevel = 90;
能不能说说 lane 模型?
Lane模型的源码在ReactFiberLane.js,源码中大量使用了位运算。Lane类型被定义为二进制变量,利用了位掩码的特性,在频繁运算的时候占用内存少,计算速度快。Lane是对于expirationTime的重构,以前使用expirationTime表示的字段,都改为了lane。renderExpirationtime -> renderLanes update.expirationTime -> update.lane fiber.expirationTime -> fiber.lanes fiber.childExpirationTime -> fiber.childLanes root.firstPendingTime and root.lastPendingTime -> fiber.pendingLanesLanes把任务优先级从批量任务中分离出来,可以更方便的判断单个任务与批量任务的优先级是否重叠:// 判断: 单task与batchTask的优先级是否重叠 //1. 通过expirationTime判断 const isTaskIncludedInBatch = priorityOfTask >= priorityOfBatch; //2. 通过Lanes判断 const isTaskIncludedInBatch = (task & batchOfTasks) !== 0; // 当同时处理一组任务, 该组内有多个任务, 且每个任务的优先级不一致 // 1. 如果通过expirationTime判断. 需要维护一个范围(在Lane重构之前, 源码中就是这样比较的) const isTaskIncludedInBatch = taskPriority <= highestPriorityInRange && taskPriority >= lowestPriorityInRange; //2. 通过Lanes判断 const isTaskIncludedInBatch = (task & batchOfTasks) !== 0;Lanes使用单个 32 位二进制变量即可代表多个不同的任务,也就是说一个变量即可代表一个组(group),如果要在一个 group 中分离出单个 task,非常容易。现在有如下场景: 有 3 个任务,其优先级
A > B > C,正常来讲只需要按照优先级顺序执行就可以了。 但是现在情况变了: A 和 C 任务是CPU密集型,而 B 是IO密集型(Suspense 会调用远程 api,算是 IO 任务),即A(cpu) > B(IO) > C(cpu)。此时的需求需要将任务B从 group 中分离出来,先处理 cpu 任务A和C。// 从group中删除或增加task //1. 通过expirationTime实现 // 0) 维护一个链表, 按照单个task的优先级顺序进行插入 // 1) 删除单个task(从链表中删除一个元素) task.prev.next = task.next; // 2) 增加单个task(需要对比当前task的优先级, 插入到链表正确的位置上) let current = queue; while (task.expirationTime >= current.expirationTime) { current = current.next; } task.next = current.next; current.next = task; // 3) 比较task是否在group中 const isTaskIncludedInBatch = taskPriority <= highestPriorityInRange && taskPriority >= lowestPriorityInRange; // 2. 通过Lanes实现 // 1) 删除单个task batchOfTasks &= ~task; // 2) 增加单个task batchOfTasks |= task; // 3) 比较task是否在group中 const isTaskIncludedInBatch = (task & batchOfTasks) !== 0;通过上述伪代码,可以看到
Lanes的优越性,运用起来代码量少,简洁高效。可以得到如下结论:
- 可以使用的比特位一共有 31 位(最高位是符号位)。
- 共定义了18 种车道(Lane/Lanes)变量,每一个变量占有 1 个或多个比特位,分别定义为
Lane和Lanes类型。 - 每一种车道(
Lane/Lanes)都有对应的优先级,所以源码中定义了 18 种优先级(LanePriority)。 - 占有低位比特位的
Lane变量对应的优先级越高- 最高优先级为
SyncLanePriority对应的车道为SyncLane = 0b0000000000000000000000000000001. - 最低优先级为
OffscreenLanePriority对应的车道为OffscreenLane = 0b1000000000000000000000000000000.
- 最高优先级为
考点2:转换体系
React 中 ReactPriorityLevel 有什么作用?
为了能协同调度中心(
scheduler包)和 fiber 树构造(react-reconciler包)中对优先级的使用,则需要转换SchedulerPriority和LanePriority,转换的桥梁正是ReactPriorityLevel。// 把 SchedulerPriority 转换成 ReactPriorityLevel export function getCurrentPriorityLevel(): ReactPriorityLevel { switch (Scheduler_getCurrentPriorityLevel()) { case Scheduler_ImmediatePriority: return ImmediatePriority; case Scheduler_UserBlockingPriority: return UserBlockingPriority; case Scheduler_NormalPriority: return NormalPriority; case Scheduler_LowPriority: return LowPriority; case Scheduler_IdlePriority: return IdlePriority; default: invariant(false, 'Unknown priority level.'); } } // 把 ReactPriorityLevel 转换成 SchedulerPriority function reactPriorityToSchedulerPriority(reactPriorityLevel) { switch (reactPriorityLevel) { case ImmediatePriority: return Scheduler_ImmediatePriority; case UserBlockingPriority: return Scheduler_UserBlockingPriority; case NormalPriority: return Scheduler_NormalPriority; case LowPriority: return Scheduler_LowPriority; case IdlePriority: return Scheduler_IdlePriority; default: invariant(false, 'Unknown priority level.'); } }export function schedulerPriorityToLanePriority( schedulerPriorityLevel: ReactPriorityLevel, ): LanePriority { switch (schedulerPriorityLevel) { case ImmediateSchedulerPriority: return SyncLanePriority; // ... 省略部分代码 default: return NoLanePriority; } } export function lanePriorityToSchedulerPriority( lanePriority: LanePriority, ): ReactPriorityLevel { switch (lanePriority) { case SyncLanePriority: case SyncBatchedLanePriority: return ImmediateSchedulerPriority; // ... 省略部分代码 default: invariant( false, 'Invalid update priority: %s. This is a bug in React.', lanePriority, ); } }
调度原理
考点1:核心
说说 React 的调度过程?
调度中心最核心的代码,在SchedulerHostConfig.default.js中。该 js 文件一共导出了 8 个函数,最核心的逻辑,就集中在这 8 个函数中 :
export let requestHostCallback; // 请求及时回调: port.postMessage export let cancelHostCallback; // 取消及时回调: scheduledHostCallback = null export let requestHostTimeout; // 请求延时回调: setTimeout export let cancelHostTimeout; // 取消延时回调: cancelTimeout export let shouldYieldToHost; // 是否让出主线程(currentTime >= deadline && needsPaint): 让浏览器能够执行更高优先级的任务(如ui绘制, 用户输入等) export let requestPaint; // 请求绘制: 设置 needsPaint = true export let getCurrentTime; // 获取当前时间 export let forceFrameRate; // 强制设置 yieldInterval (让出主线程的周期). 这个函数虽然存在, 但是从源码来看, 几乎没有用到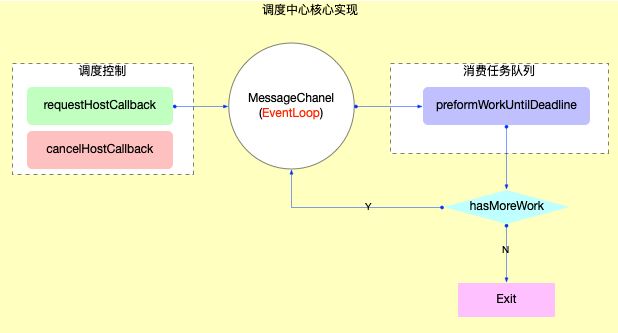
重点介绍其中的
及时回调:// 接收 MessageChannel 消息 const performWorkUntilDeadline = () => { // ...省略无关代码 if (scheduledHostCallback !== null) { const currentTime = getCurrentTime(); // 更新deadline deadline = currentTime + yieldInterval; // 执行callback scheduledHostCallback(hasTimeRemaining, currentTime); } else { isMessageLoopRunning = false; } }; // 宏任务 const channel = new MessageChannel(); const port = channel.port2; channel.port1.onmessage = performWorkUntilDeadline; // 请求回调 requestHostCallback = function(callback) { // 1. 保存callback scheduledHostCallback = callback; if (!isMessageLoopRunning) { isMessageLoopRunning = true; // 2. 通过 MessageChannel 发送消息 port.postMessage(null); } }; // 取消回调 cancelHostCallback = function() { scheduledHostCallback = null; };很明显,请求回调之后
scheduledHostCallback = callback,然后通过MessageChannel发消息的方式触发performWorkUntilDeadline函数,最后执行回调scheduledHostCallback。由于
MessageChannel是宏任务,需要等到当前同步代码执行完后才触发performWorkUntilDeadline进行调度,故体现为异步。
考点2:任务队列
任务队列是如何管理与实现的?
在Scheduler.js中,维护了一个taskQueue,任务队列管理就是围绕这个
taskQueue展开:// Tasks are stored on a min heap var taskQueue = []; var timerQueue = [];源码中除了
taskQueue队列之外还有一个timerQueue队列。这个队列是预留给延时任务使用的,在react@17.0.2版本里面,从源码中的引用来看,算一个保留功能,没有用到。在
unstable_scheduleCallback函数中,创建任务:// 省略部分无关代码 function unstable_scheduleCallback(priorityLevel, callback, options) { // 1. 获取当前时间 var currentTime = getCurrentTime(); var startTime; if (typeof options === 'object' && options !== null) { // 从函数调用关系来看, 在v17.0.2中,所有调用 unstable_scheduleCallback 都未传入options // 所以省略延时任务相关的代码 } else { startTime = currentTime; } // 2. 根据传入的优先级, 设置任务的过期时间 expirationTime var timeout; switch (priorityLevel) { case ImmediatePriority: timeout = IMMEDIATE_PRIORITY_TIMEOUT; break; case UserBlockingPriority: timeout = USER_BLOCKING_PRIORITY_TIMEOUT; break; case IdlePriority: timeout = IDLE_PRIORITY_TIMEOUT; break; case LowPriority: timeout = LOW_PRIORITY_TIMEOUT; break; case NormalPriority: default: timeout = NORMAL_PRIORITY_TIMEOUT; break; } var expirationTime = startTime + timeout; // 3. 创建新任务 var newTask = { id: taskIdCounter++, callback, priorityLevel, startTime, expirationTime, sortIndex: -1, }; if (startTime > currentTime) { // 省略无关代码 v17.0.2中不会使用 } else { newTask.sortIndex = expirationTime; // 4. 加入任务队列 push(taskQueue, newTask); // 5. 请求调度 if (!isHostCallbackScheduled && !isPerformingWork) { isHostCallbackScheduled = true; requestHostCallback(flushWork); } } return newTask; }重点分析
task对象的各个属性:var newTask = { id: taskIdCounter++, // id: 一个自增编号 callback, // callback: 传入的回调函数 priorityLevel, // priorityLevel: 优先级等级 startTime, // startTime: 创建task时的当前时间 expirationTime, // expirationTime: task的过期时间, 优先级越高 expirationTime = startTime + timeout 越小 sortIndex: -1, }; newTask.sortIndex = expirationTime; // sortIndex: 排序索引, 全等于过期时间。保证过期时间越小, 越紧急的任务排在最前面创建任务之后,最后请求调度
requestHostCallback(flushWork),flushWork函数作为参数被传入调度中心内核等待回调。// 省略无关代码 function flushWork(hasTimeRemaining, initialTime) { // 1. 做好全局标记, 表示现在已经进入调度阶段 isHostCallbackScheduled = false; isPerformingWork = true; const previousPriorityLevel = currentPriorityLevel; try { // 2. 循环消费队列 return workLoop(hasTimeRemaining, initialTime); } finally { // 3. 还原全局标记 currentTask = null; currentPriorityLevel = previousPriorityLevel; isPerformingWork = false; } }flushWork中调用了workLoop。队列消费的主要逻辑是在workLoop函数中,这就是React 工作循环中提到的任务调度循环。// 省略部分无关代码 function workLoop(hasTimeRemaining, initialTime) { let currentTime = initialTime; // 保存当前时间, 用于判断任务是否过期 currentTask = peek(taskQueue); // 获取队列中的第一个任务 while (currentTask !== null) { if ( currentTask.expirationTime > currentTime && (!hasTimeRemaining || shouldYieldToHost()) ) { // 虽然currentTask没有过期, 但是执行时间超过了限制(毕竟只有5ms, shouldYieldToHost()返回true). 停止继续执行, 让出主线程 break; } const callback = currentTask.callback; if (typeof callback === 'function') { currentTask.callback = null; currentPriorityLevel = currentTask.priorityLevel; const didUserCallbackTimeout = currentTask.expirationTime <= currentTime; // 执行回调 const continuationCallback = callback(didUserCallbackTimeout); currentTime = getCurrentTime(); // 回调完成, 判断是否还有连续(派生)回调 if (typeof continuationCallback === 'function') { // 产生了连续回调(如fiber树太大, 出现了中断渲染), 保留currentTask currentTask.callback = continuationCallback; } else { // 把currentTask移出队列 if (currentTask === peek(taskQueue)) { pop(taskQueue); } } } else { // 如果任务被取消(这时currentTask.callback = null), 将其移出队列 pop(taskQueue); } // 更新currentTask currentTask = peek(taskQueue); } if (currentTask !== null) { return true; // 如果task队列没有清空, 返回ture. 等待调度中心下一次回调 } else { return false; // task队列已经清空, 返回false. } }时间切片原理:
消费任务队列的过程中,可以消费
1~n个 task,甚至清空整个 queue。但是在每一次具体执行task.callback之前都要进行超时检测,如果超时可以立即退出循环并等待下一次调用。可中断渲染原理:
在时间切片的基础之上,如果单个
task.callback执行时间就很长(假设 200ms)。就需要task.callback自己能够检测是否超时,所以在 fiber 树构造过程中,每构造完成一个单元,都会检测一次超时,如遇超时就退出fiber树构造循环,并返回一个新的回调函数(就是此处的continuationCallback)并等待下一次回调继续未完成的fiber树构造。
考点3:节流防抖
React 是如何保证调度性能的?
reconciler
注册调度任务的核心逻辑位于ensureRootIsScheduled函数中。正常情况下,ensureRootIsScheduled函数会与scheduler包通信,最后注册一个task并等待回调。// ... 省略部分无关代码 function ensureRootIsScheduled(root: FiberRoot, currentTime: number) { // 前半部分: 判断是否需要注册新的调度 const existingCallbackNode = root.callbackNode; const nextLanes = getNextLanes( root, root === workInProgressRoot ? workInProgressRootRenderLanes : NoLanes, ); const newCallbackPriority = returnNextLanesPriority(); if (nextLanes === NoLanes) { return; } // 节流防抖 if (existingCallbackNode !== null) { const existingCallbackPriority = root.callbackPriority; if (existingCallbackPriority === newCallbackPriority) { return; } cancelCallback(existingCallbackNode); } // 后半部分: 注册调度任务 省略代码... // 更新标记 root.callbackPriority = newCallbackPriority; root.callbackNode = newCallbackNode; }在
task注册完成之后, 会设置fiberRoot对象上的属性,代表现在已经处于调度进行中。再次进入
ensureRootIsScheduled时(比如连续 2 次setState,第 2 次setState同样会触发reconciler中的调度阶段),如果发现处于调度中,则需要一些节流和防抖措施,进而保证调度性能。- 节流(判断条件:
existingCallbackPriority === newCallbackPriority,新旧更新的优先级相同, 如连续多次执行setState),则无需注册新task(继续沿用上一个优先级相同的task),直接退出调用。 - 防抖(判断条件:
existingCallbackPriority !== newCallbackPriority,新旧更新的优先级不同), 则取消旧task,重新注册新task。
- 节流(判断条件:
HOOK 原理
考点1:Hook 结构
Hook 与 Fiber 是什么关系?
使用 Hook 最终也是为了控制 fiber 节点的状态和副作用。从 fiber 视角,相关的属性如下:
export type Fiber = {| // 1. fiber节点自身状态相关 pendingProps: any, memoizedProps: any, updateQueue: mixed, memoizedState: any, // 2. fiber节点副作用(Effect)相关 flags: Flags, nextEffect: Fiber | null, firstEffect: Fiber | null, lastEffect: Fiber | null, |};再看看
Hook的数据结构:type Update<S, A> = {| lane: Lane, action: A, eagerReducer: ((S, A) => S) | null, eagerState: S | null, next: Update<S, A>, priority?: ReactPriorityLevel, |}; type UpdateQueue<S, A> = {| pending: Update<S, A> | null, dispatch: (A => mixed) | null, lastRenderedReducer: ((S, A) => S) | null, lastRenderedState: S | null, |}; export type Hook = {| memoizedState: any, // 当前状态 baseState: any, // 基状态 baseQueue: Update<any, any> | null, // 基队列 queue: UpdateQueue<any, any> | null, // 更新队列 next: Hook | null, // next指针 |};从定义来看,
Hook对象共有 5 个属性:hook.memoizedState: 保持在内存中的局部状态。hook.baseState:hook.baseQueue中所有update对象合并之后的状态。hook.baseQueue: 存储update对象的环形链表,只包括高于本次渲染优先级的update对象。hook.queue: 存储update对象的环形链表,包括所有优先级的update对象。hook.next:next指针,指向链表中的下一个hook。
所以
Hook是一个链表,单个Hook拥有自己的状态hook.memoizedState和自己的更新队列hook.queue。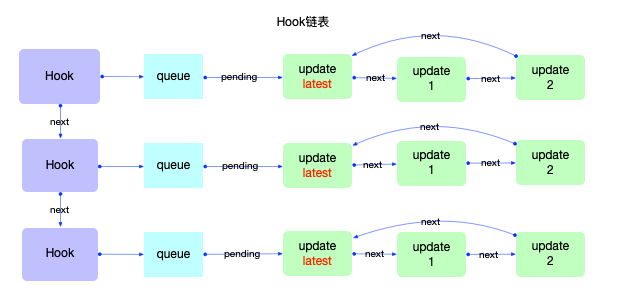
function类型的fiber节点(函数组件),通过renderWithHooks调用function。在
function中通过Hook Api(如:useState, useEffect)创建Hook对象,最终Hook链表将会挂载到fiber.memoizedState之上。每次 fiber 树更新阶段,
Hook都经过了一次克隆:fiber 树在构造时,以双缓冲技术为基础,会将
current.memoizedState按照顺序克隆到workInProgress.memoizedState中。Hook经过了一次克隆,内部的属性(hook.memoizedState等)都没有变动,所以其状态并不会丢失,实现了数据的持久化。
考点2:状态Hook
状态 Hook 具体做了什么操作?
创建 Hook:在 fiber 初次构造阶段,创建
hook对象。状态初始化:在
useState(initialState)函数内部,设置hook.memoizedState = hook.baseState = initialState;,初始状态被同时保存到了hook.baseState(合并值)和hook.memoizedState(当前值)中,最后返回[hook.memoizedState, dispatch]。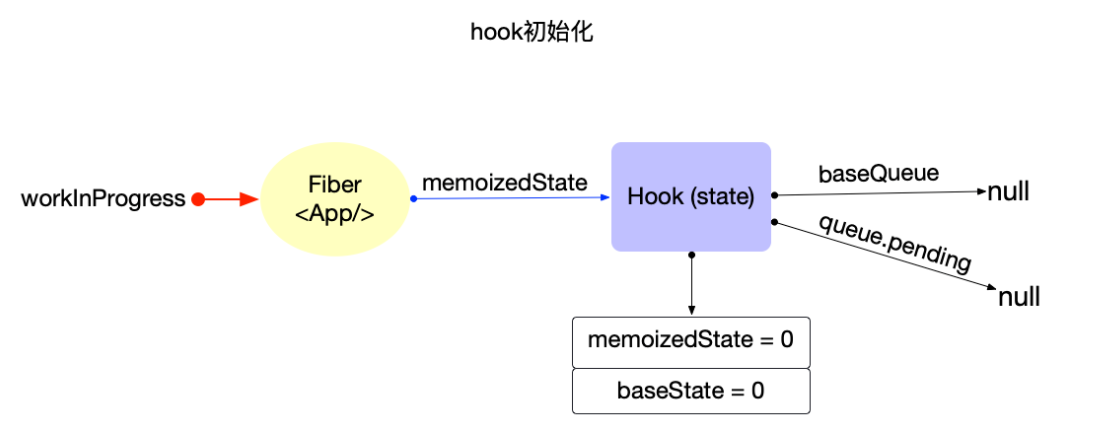
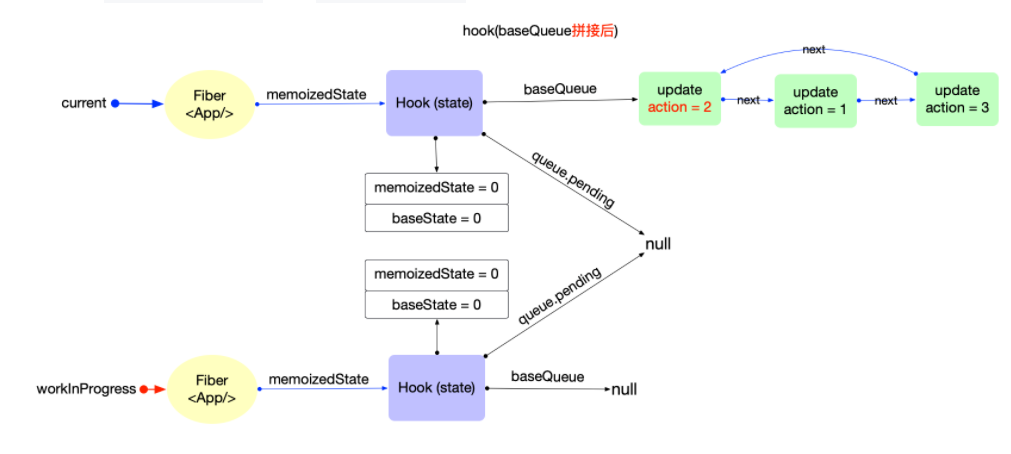
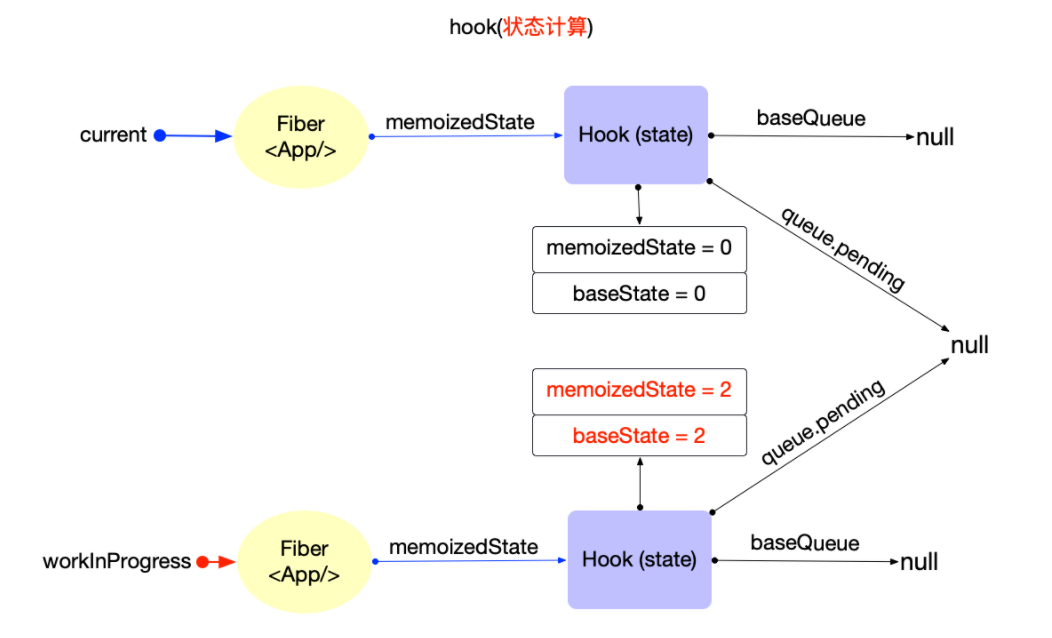
状态更新:通过
dispatch函数进行更新,创建update对象,加入hook.queue。发起调度更新,进入reconciler的输入阶段。经过scheduler调度后触发 fiber 树构造对比更新阶段,再次调用function,实际调用updateReducer。获取到hook对象后,将hook.queue.pending拼接到current.baseQueue。如果update优先级不够,加入到baseQueue中,等待下一次render,否则直接合并到hook.baseState并更新属性。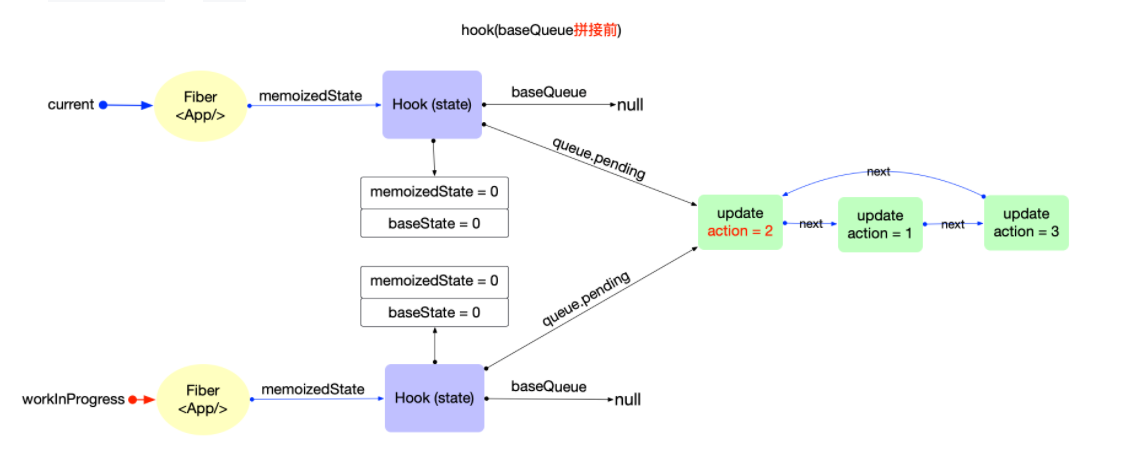
考点3:副作用Hook
副作用 Hook 是如何工作的?
创建 Hook:在 fiber 初次构造阶段,创建
hook对象。创建 Effect:创建
effect(在pushEffect中),挂载到hook.memoizedState上。function pushEffect(tag, create, destroy, deps) { // 1. 创建effect对象 const effect: Effect = { tag, create, destroy, deps, next: (null: any), }; // 2. 把effect对象添加到环形链表末尾 let componentUpdateQueue: null | FunctionComponentUpdateQueue = (currentlyRenderingFiber.updateQueue: any); if (componentUpdateQueue === null) { // 新建 workInProgress.updateQueue 用于挂载effect对象 componentUpdateQueue = createFunctionComponentUpdateQueue(); currentlyRenderingFiber.updateQueue = (componentUpdateQueue: any); // updateQueue.lastEffect是一个环形链表 componentUpdateQueue.lastEffect = effect.next = effect; } else { const lastEffect = componentUpdateQueue.lastEffect; if (lastEffect === null) { componentUpdateQueue.lastEffect = effect.next = effect; } else { const firstEffect = lastEffect.next; lastEffect.next = effect; effect.next = firstEffect; componentUpdateQueue.lastEffect = effect; } } // 3. 返回effect return effect; }effect的数据结构:export type Effect = {| tag: HookFlags, create: () => (() => void) | void,// 通过useEffect()所传入的函数 destroy: (() => void) | void, // 返回的函数,组件销毁后执行 deps: Array<mixed> | null,// 依赖项, 如果依赖项变动, 会创建新的effect next: Effect, |}; // effect.tag: 二进制属性, 代表effect的类型 export const NoFlags = /* */ 0b000; export const HasEffect = /* */ 0b001; // 有副作用, 可以被触发 export const Layout = /* */ 0b010; // Layout, dom突变后同步触发 export const Passive = /* */ 0b100; // Passive, dom突变前异步触发处理 Effect 回调:完成 fiber 树构造后,逻辑会进入渲染阶段。
- 第一阶段: DOM 变更之前,处理副作用队列中带有
Passive标记的fiber节点。 - 第二阶段: DOM 变更,界面得到更新。同步调用
effect.destroy()。 - 第三阶段: DOM 变更后。调用
effect.create()之后, 将返回值赋值到effect.destroy。
更新 Hook:假设在初次调用之后,发起更新,会再次执行
function,这时function使用的useEffect,useLayoutEffect等api也会再次执行。无论依赖是否变化,都复用之前的effect.destroy。等待commitRoot阶段的调用。- 第一阶段: DOM 变更之前,处理副作用队列中带有
- Post link: https://blog.sticla.top/2021/08/18/front-end-interview-review-react/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.
GitHub Issues